目錄
- Scrapy框架簡單介紹
- 創建Scrapy項目
- 創建Spider爬蟲
- Spider爬蟲提取數據
- items.py代碼定義字段
- fiction.py代碼提取數據
- pipelines.py代碼保存數據
- settings.py代碼啟動爬蟲
- 結果展示
Scrapy框架簡單介紹
Scrapy框架是一個基于Twisted的異步處理框架,是純Python實現的爬蟲框架,是提取結構性數據而編寫的應用框架,其架構清晰,模塊之間的耦合程度低,可擴展性極強,我們只需要少量的代碼就能夠快速抓取數據。
其框架如下圖所示:

Scrapy Engine是整個框架的核心,而涉及到我們編寫代碼的模塊一般只有Item Pipeline模塊和Spiders模塊。
創建Scrapy項目
首先我們通過以下代碼來創建Scrapy項目,執行代碼如下圖所示:
Scrapy startproject Fiction
運行結果如下圖所示:

通過上圖可知,我們在C盤創建了一個新的Scrapy項目,項目名為Fiction,而且還提示我們可以通過以下命令創建第一個Spider爬蟲,命令如下所示:
cd Fiction #進入目錄
scrapy genspider example example.com #創建spider爬蟲
其中example是我們爬蟲名,example.com是爬蟲爬取的范圍,也就是網站的域名。
Fiction文件夾內容如下圖所示:

創建Spider爬蟲
在上面的步驟我們成功創建了一個Scrapy項目,而且知道如何創建Spider爬蟲,接下來我們創建名為fiction的Spider爬蟲,其域名為www.17k.com,代碼如下所示:
scrapy genspider fiction www.17k.com
運行后,spiders文件夾中多了我們剛才創建fiction.py,這個就是我們創建的Spider爬蟲。
如下圖所示:
看到這么多py文件是不是慌了,其實不用慌,一般情況我們主要在剛創建的spider爬蟲文件、items.py和pipelines.py進行編寫代碼,其中:
fiction.py:主要編寫代碼定義爬取的邏輯,解析響應并生成提取結果和新的請求;items.py:主要先定義好爬取數據的字段,避免拼寫錯誤或者定義字段錯誤,當然我們可以不先定義好字段,而在fiction.py中直接定義;pipelines.py:主要是編寫數據清洗、驗證和存儲數據的代碼,當我們把數據存儲在csv、xml、pickle、marshal、json等文件時,就不需要在pipelines.py中編寫代碼了,只需要執行以下代碼即可:
scrapy crawl fiction 文件名.后綴
當數據需要保存在MongoDB數據庫時,則編寫以下代碼即可:
from pymongo import MongoClient
client=MongoClient()
collection=client["Fiction"]["fiction"]
class Test1Pipeline:
def process_item(self, item, spider):
collection.insert(item)
return item
Spider爬蟲提取數據
在提取數據前,首先我們進入要爬取小說網站并打開開發者工具,如下圖所示:
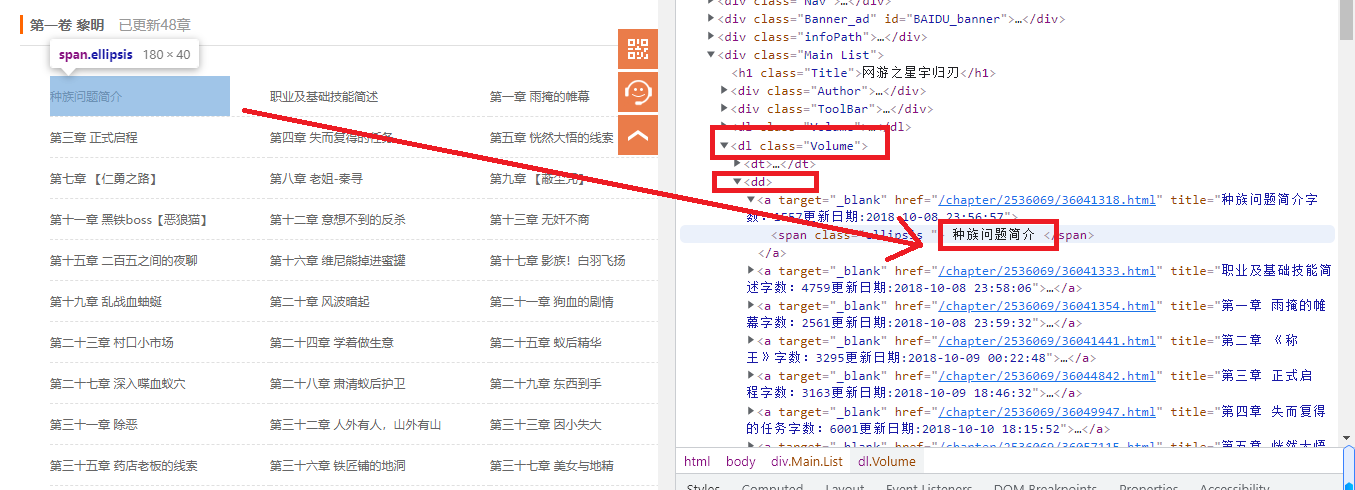
我們通過上圖可以發現,dl class="Volume">存放著我們所有小說章節名,點擊該章節就可以跳轉到對應的章節頁面,所以可以使用Xpath來通過這個div作為我們的xpath爬取范圍,通過for循環來遍歷獲取每個章節的名和URL鏈接。
跳轉章節內容頁面后,打開開發者工具,如下圖所示:
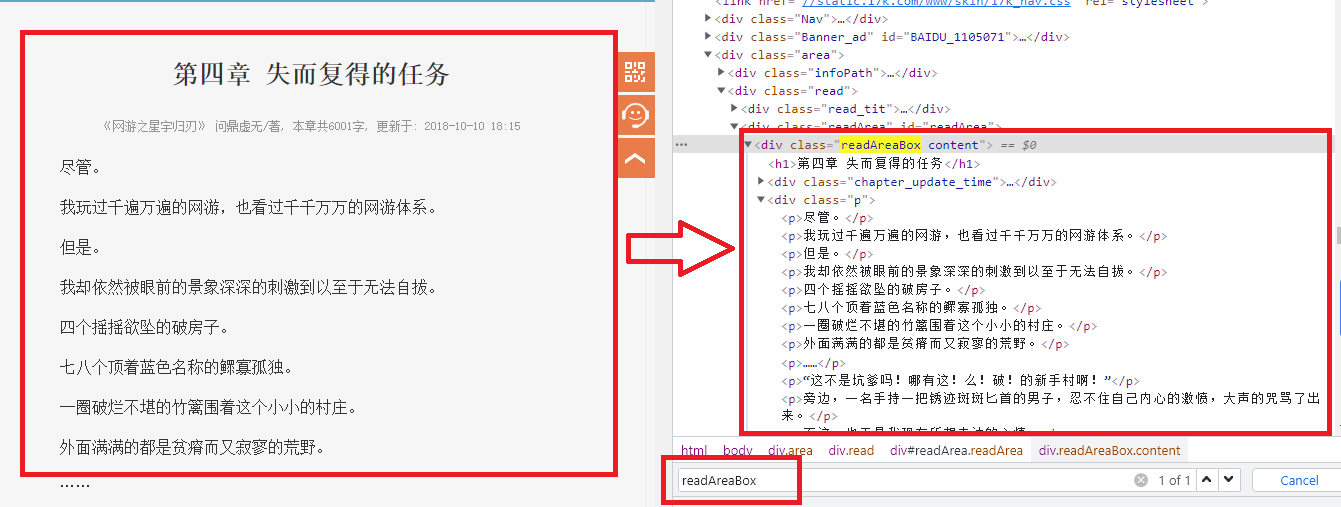
通過上圖可以發現,小說內容存儲在div class="readAreaBox">里面,我們可以通過for循環來遍歷該dl中的div class="p">獲取到章節的全部內容,當然也是通過使用Xpath來獲取。
items.py代碼定義字段
細心的小伙伴就發現了,我們所需要提前的字段有章節名、章節URL鏈接和章節內容,其中章節名和章節內容是需要進行數據保存的,所以可以先在items.py文件中定義好字段名,具體代碼如下所示:
import scrapy
class FictionItem(scrapy.Item):
# define the fields for your item here like:
name = scrapy.Field()
text = scrapy.Field()
定義字段很簡單,字段名=scrapy.Field()即可。
對了,在items.py定義好字段有個最好的好處是當我們在獲取到數據的時候,使用不同的item來存放不同的數據,在把數據交給pipeline的時候,可以通過isinstance(item,FictionItem)來判斷數據屬于哪個item,進行不同的數據(item)處理。
定義好字段后,這是我們通過在pipeline.py文件中編寫代碼,對不同的item數據進行區分,具體代碼如下:
from Fiction.items import FictionItem
class FictionPipeline:
def process_item(self, item, spider):
if isinstance(item,FictionItem):
print(item)
當然,在我們爬取的項目中,只需要一個class類,在上面的代碼只是為了展示如何判斷區分數據屬于哪個item。
fiction.py代碼提取數據
fiction.py文件也就是我們創建的spider爬蟲,打開fiction.py文件,其代碼內容如下所示:
import scrapy
class FictionSpider(scrapy.Spider):
name = 'fiction'
allowed_domains = ['www.17k.com']
start_urls = ['http://www.17k.com/']
def parse(self, response):
pass
其中:
name是定義此爬蟲名稱的字符串,每個項目唯一的名字,用來區分不同的Spider,啟動爬蟲時使用scrapy crawl +該爬蟲名字;allowed_domains是允許爬取的域名,防止爬蟲爬到其他網站;start_urls是最開始爬取的url;parse()方法是負責解析返回響應、提取數據或進一步生成要處理的請求,注意:不能修改這個方法的名字。
大致了解該文件內容的各個部分后,我們開始提取首頁的章節名和章節URL鏈接,具體代碼如下所示:
import scrapy
from Fiction.items import FictionItem
class FictionSpider(scrapy.Spider):
name = 'fiction'
allowed_domains = ['www.17k.com']
start_urls = ['https://www.17k.com/list/2536069.html']
def parse(self, response):
html = response.xpath('//dl[@class="Volume"]')
books = html.xpath('./dd/a')
for book in books:
item =FictionItem()
item['name'] = []
name = book.xpath('./span/text()').extract()
for i in name:
item['name'].append(i.replace('\n', '').replace('\t', ''))
href = book.xpath('./@href').extract_first()
+ href
yield scrapy.Request(url=href, callback=self.parse_detail, meta={'item': item})
首先導入FictionItem,再我們把start_urls鏈接修改為待會要爬的URL鏈接,在parse()方法中,使用xpath獲取章節名和章節URL鏈接,通過for循環調用FictionItem(),再把章節名存放在item里面。
通過生成器yield 返回調用scrapy.Request()方法,其中:
url=href:表示下一個爬取的URL鏈接;callback:表示指定parse_detail函數作為解析處理;meta:實現在不同的解析函數中傳遞數據。
在上一步中我們指定了parse_detail函數作為解析處理,接下來將編寫parse_detail函數來獲取章節內容,具體代碼如下所示:
def parse_detail(self,response):
string=""
item=response.meta['item']
content=response.xpath('//*[@id="readArea"]/div[1]/div[2]//p/text()').extract()
for i in content:
string=string+i+'\n'
item['text']=string
yield item
首先我們定義了一個空變量string,在通過response.meta[]來接收item數據,其參數為上一步中的meta={'item': item}的item,接下來獲取章節內容,最后將章節內容存儲在item['text']中,并通過生成器yield返回數據給引擎。
pipelines.py代碼保存數據
章節名和章節內容已經全部獲取下來了,接下來我們把獲取下來的數據保存為txt文件,具體代碼如下所示:
from Fiction.items import FictionItem
import time
class FictionPipeline:
def open_spider(self, spider):
print(time.time())
def process_item(self, item, spider):
if isinstance(item, FictionItem):
title = item['name']
content = item['text']
with open(f'小說/{title[0]}.txt', 'w', encoding='utf-8')as f:
f.write(content)
def close_spider(self, spider):
print(time.time())
首先我們導入FictionItem、time,在open_spider()和close_spider()方法編寫代碼調用time.time()來獲取爬取的開始時間和結束時間,再在process_item()方法中,把引擎返回的item['name']和item['text']分別存放在title和content中,并通過open打開txt文件,調用write()把章節內容寫入在txt文件中。
settings.py代碼啟動爬蟲
在啟動爬蟲前,我們先要在settings.py文件中啟動引擎,啟動方式很簡單,只要找到下圖中的代碼,并取消代碼的注釋即可:

有人可能問:那User-Agent在哪里設置?我們可以在settings.py文件中,設置User-Agent,具體代碼如下:

好了,所有代碼已經編寫完畢了,接下來將啟動爬蟲了,執行代碼如下:
啟動爬蟲后,發現我們控制臺里面多了很多log日志數據的輸出,這時可以通過在settings.py添加以下代碼,就可以屏蔽這些log日志:
結果展示
好了,scrapy框架爬取小說就講到這里了,感覺大家的觀看!!!
更多關于Python爬蟲教程Scrapy框架爬取的資料請關注腳本之家其它相關文章!
您可能感興趣的文章:- python實現爬蟲抓取小說功能示例【抓取金庸小說】
- Python scrapy爬取小說代碼案例詳解
- Python scrapy爬取起點中文網小說榜單
- Python爬蟲框架Scrapy基本用法入門教程
- 零基礎寫python爬蟲之使用Scrapy框架編寫爬蟲
